Management basics
This document contains a guide to manage your DBOD instance in the DBOD web interface.
Actions executed by jobs
When you perform certain actions on one of the instances you are authorised to manage, a job is created in the system. This job will be dispatched as soon as possible, the execution time varies depending on the action performed. After the execution, the result of the job will be displayed in the "Jobs" tab in JSON format. The "Jobs" tab keeps the historical data for the last 10000 jobs.
Actions executed by DBOD API
Some other actions, like changing instance attributes (description, expiry date,etc.) or enabling/disabling alerts are managed through http request to the DBOD internal API, and will be dispatched immediately. The changes will be reflected instantly as long as the change is applied with success.
You can edit all the properties of your instance with an editable text field. It suffices to place the focus in the desired text field and update its content. On focus change, you will be prompted in a dialog to confirm the changes.
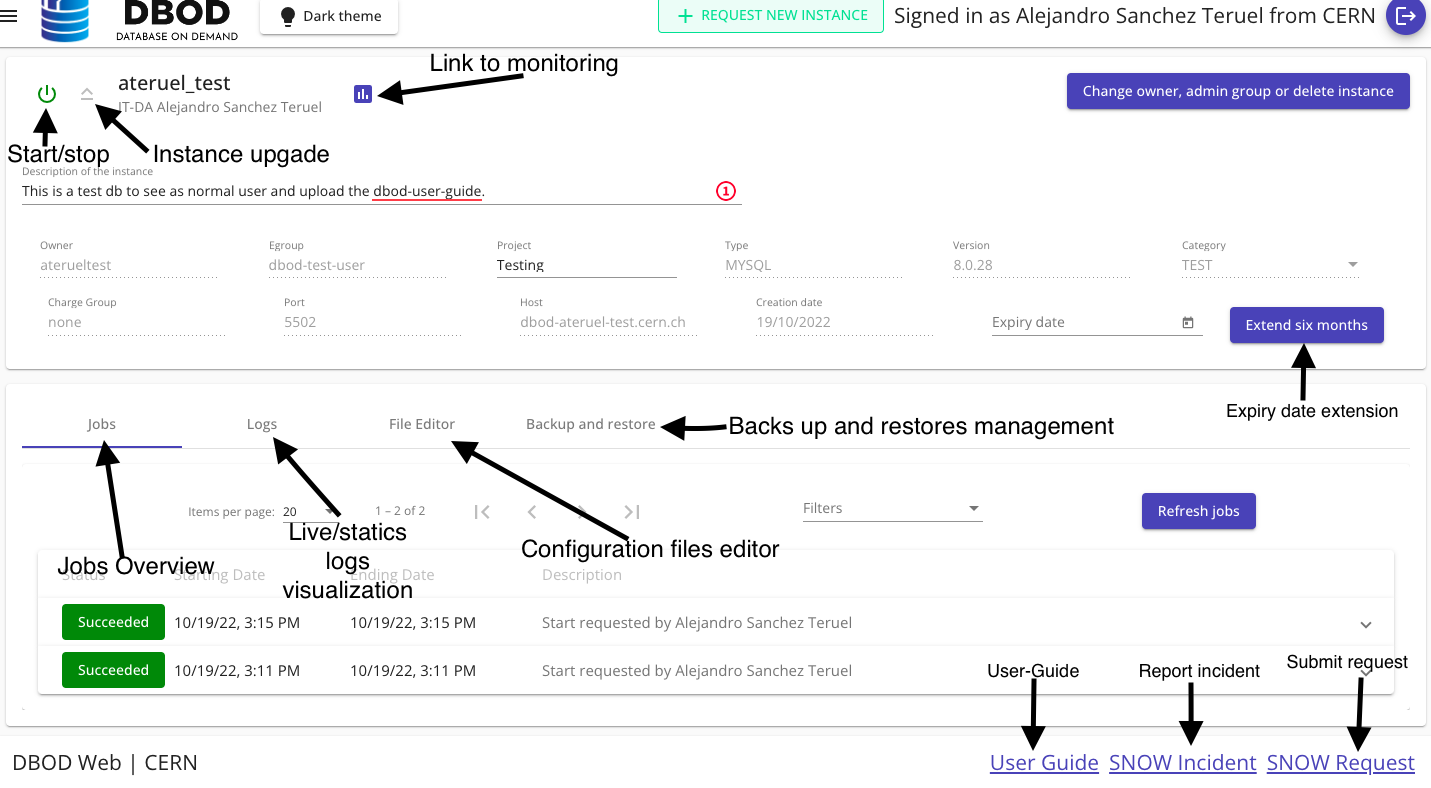
Available actions will be described in next pages.
Actions can timeout while waiting to start
Historically some tasks like upgrading or cloning of an instance were going to start a job immediately, once triggered from the DBOD web interface.
Behind the scenes, these jobs can execute a number of operations in our infrastructre and in the host where the instance is running.
For example, in some cases, one or more puppet runs are required to apply changes to the host and the instance configuration.
Random failures can occur when multiple jobs, running concurrently on the same host, are attempting to disable, run or enable puppet, in a random order, at the same time.
With hundreds of instances in need of an upgrade and/or cloning for testing purposes, the probability of clashing among instances sharing the same host are not negligible.
We are well aware that such failures can be quite annoying for DBOD users, but even more they are burdening our team with SNOW tickets and interventions to fix and restart the requested operations.
With the aim of mitigating the impact and reduce the occurrence of failures, we have implemented a lock logic, which should sequence the access to the host of those operations requiring exclusive access.
This means that when a job has has locked the host, others jobs will queue and attempt multiple times to get the lock, until the lock is acquired or a timeout is expired or the maximum number of attempts is reached.
Info
For most operations the timeout is set to 30 minutes: if an upgrade is triggered, but another operation has acquired the lock on the host, the upgrade will retry multiple times, but eventually will fail, after 30 minutes.
In our intentions, 30 minutes should be a good compromise between having some chances of getting the lock, while allowing an owner to cancel a planned OTG, if the upgrade did not start in time.
On the other hand, if strict time constraints are not an issue, it should be safe retrying a few times the failed operation, provided it failed just after 30 minutes, until it goes through.
Warning
If you are in doubt or can not afford to retry more, please get in touch by opening a SNOW ticket with our team
This is our first attempt (and iteration) at tackling these issues. We have already some idea for improving the solution but we have also a number of priorities and limited resources.
Nevertheless, we are always glad to hear from our users, especially to receiving constructive feedbacks and suggestions, which we strive to take in consideration.